New Digits
We've explored what exactly place notation is, and what the best base for using place notation with is; namely, twelve. But that leaves us with two problems: one, what to call our new numbers; but more immediately, how we write them. In other words, what new digits will we have?
Saying Numbers
This problem has been solved very thoroughly, simply, and satisfactorily with Systematic Dozenal Nomenclature (SDN), which we explore in our section on Dozenal Applications. For the purposes of this article, however, we will proceed simply, in what is euphemistically called "plain English."
We will count as normal: one, two, three, four, five, six, seven, eight, nine, ten, eleven. After eleven, we come to our base, twelve; this we will call simply "a dozen." We will then count as follows: one dozen one, one dozen two, one dozen three, and so forth, until we reach one dozen ten, one dozen eleven, two dozen. This will take us as far as eleven dozen eleven (in decimal, one hundred and forty-three).
But even after eleven dozen eleven, we may continue using so-called "plain English," because English has a word for a dozen dozen: a gross. So we will count from eleven dozen eleven, to one gross, to one gross one dozen and four, and so forth.
Our simple discussion here will rarely require it, but a dozen gross has traditionally been called a "great gross," and we can proceed using this as necessary. Higher powers of a dozen than this can be formed by combining these simple words; "76549," for example, would be read "seven dozen great-gross, six great-gross, five gross, four dozen, and nine." This is wordy and sub-optimal, but it will function well enough for our current purposes, until SDN can be introduced.
Without further ado, let us consider new digits.
Least Change vs. Separate Identity
Since the beginning of dozenalism's revival in the first half of the twentieth century, there has been a conflict between two schools of thought on new symbols; these two schools were labelled "least change" as opposed to "separate identity" by a pioneering dozenalist and early member of the Dozenal Society of America, Ralph Beard.
The "least change" school argues that we ought to introduce as few new digits as possible when we're deciding how to write out our numbers. This means that our current set of digits, 0--9, should be retained in their entirety, changing nothing. The only new digits we really need, by this school of thought, are digits for ten and eleven. Differentiating between dozenal and other-base numbers can be done explicitly (e.g., by saying "this number is in dozenal") or by some other means (preceding numbers in this or that base by some special mark, like an asterisk, or use of a distinguishing fractional point, such as ";" rather than ".").
The "separate identity" school, on the other hand, argues that dozenalists should differentiate their numbers as much as possible from those of other bases. They therefore advocate a completely new set of digits for 0--9 as well as for ten and eleven. This will not only clearly differentiate dozenal numbers from those in other bases, but it will provide a completely new system for people to adopt and understand. People, they argue, will look at "10" and see "ten"; it will be difficult to convince them that in other bases it means something else. A separate identity would avoid this problem.
There is a sliding scale from one of these schools to the other, of course; proposals have ranged from only two new digits, to six new digits, to all new digits.
In the grand scheme of things, the "least change" school seems to have won the day; one rarely sees proposals for complete new sets of digits. There are a number of significant advantages to a least change approach, as well, which outweigh those of separate identity proposals.
- The learning curve for dozenal is minimized. One need not teach new dozenalists an entirely new set of numerals; one need only teach two new ones, and provided that these are well chosen, this makes seeing dozenal numbers as "normal" numbers easier.
- The design challenges are simpler. It is easier to design two new digits to fit in with ten old ones than to develop an entirely new set which fits well with each other as well as with existing alphabets.
- The advantage of separate identity proposals---that dozenal numbers are easily distinguished as such---can easily be achieved within least change proposals, by the use of some identifying mark (usually "*"), by writing dozenal numbers in a different face (such as italics), or by the use of a distinguishing fractional point (often erroneously called a "decimal" point), usually ";".
This article, therefore, adopts the least change approach in its discussion of new digits. We will, then, only be considering good choices for two digits; namely, ten and eleven.
ASCII and "Plain Text"
Most of the time, the above two phrases are synonymous. Strictly speaking, however, ASCII is the American Standard Code for Information Interchange, an encoding scheme which came to dominating most of computer interactions (which it still does, really, today). In technical terms, this is a seven-bit encoding, which allows only ten dozen and seven (decimal, one hundred and twenty-seven) characters. As such, it is fairly limited in the characters it can encode. If you are typing on a U.S. standard keyboard, almost all of the symbols you are typing are plain ASCII. A table showing the permitted characters can be found easily.
Because most people still use computers in ASCII, or some eight-bit encoding including ASCII as a subset, it's important that we have a set of characters which can be used within it. This means we are limited to choosing characters for our new digits from the 127 characters ASCII allows. In print, we have more leeway; but we must have something which will work and be recognizable within a "plain-text" only framework.
What characters, then, do we have to choose from when limited to ASCII characters?
- ASCII code points 0--27 (dozenal; that's zero to two dozen seven), plus ten dozen and seven, are "control characters," characters like tabs, backspaces, and the like. Many of these are rarely used (such as vertical tabs); others are extremely common, such as horizontal tabs and carriage returns. All of them, however, are "non-printing"; they don't show up visibly. So these are not options for us.
- Code point 28 (two dozen and eight) is a space; again, this is clearly not an option for us.
- Code points four dozen to four dozen nine are the digits we're already familiar with (0--9).
- Code points two dozen and nine to two dozen and eleven;
four dozen and ten to five dozen and four; seven dozen
and seven to eight dozen; and ten dozen three to ten dozen
six are punctuation characters:
! " # $ % & ' ( ) * + , - . / : ; < = > ? @ [ \ ] ^ _ ` { | } ~ Some of these characters represent distinct possibilities for us. - Code points five dozen and five to seven dozen and six are the capital letters (A--Z). Eight dozen and one to ten dozen and two are the lowercase letters (a--z). These are also possibilities for new digits.
So we are left with punctuation schemes and letters for useful new digits in ASCII. We need choose only two for a complete system. Some of the systems that have been used in the past will be examined now.
The "Bell" System
For a significant part of the last century, the Bell Telephone Company had a government-supported monopoly on the phone system in the United States. Given that the United States was a leader in telecommunications technology, this meant that Bell equipment was quite well-known even outside of North America. Bell issued a telephone with a standard keypad; that keypad included the digits 0--9, but also two other characters, "*" (called a "star" or an "asterisk") and "#" (called "pound" or "octothorpe," and more recently, in computer fields, a "hash"). This led to four rows of three keys each; in other words, a dozen. For a time, the DSA decided that this was a possible segway into mainstreaming dozenalism and adopted "*" and "#" as the characters used for ten and eleven.
Nor was the process entirely without merit. The asterisk can easily be seen to be a simple crossed "X" (and thus only a minor variation from the DSA's traditional symbol), while the octothorpe can be interpreted as a double-crossed eleven (two vertical lines crossed with two horizontal ones), and thus an easy character to learn.
However, these characters suffer from some serious flaws. First, they were not always found on foreign typewriters, nor are they now on foreign keyboards. Second, they do not fit in well with the other digits; in other words, they really look like punctuation, not like characters:
The British System
This system, which I have called "British" only because it has historically been common in Great Britain but uncommon elsewhere, uses the initial letters of the words "ten" and "eleven" (usually capitalized) as its new digits. In other words, "T" is the digit ten and "E" is the digit eleven.
This is elegant in its simplicity on one level, but still somewhat lacking on another. Simply using the first letters of the words seems easy to understand; however, we are simply not used to thinking "ten" upon seeing "T." As for eleven, it is hard to imagine a better system, at least for our language, when limited to the ASCII character set. It meshes with our other digits as well as any character in that limited set can, and is connected enough with the word "eleven" that it presents a good enough standby when we are limited to that set.
Early DSA
For the first few dozen years of the Dozenal Society of America, the character "X" was used for ten and "E" for eleven. This is the best of the proposed systems.
F. Emerson Andrews proposed these characters, and used them extensively, in his groundbreaking article An Excursion in Numbers, which provided the impetus for the modern expansion of the dozenal movement. "X" has an important feature than "T" simply doesn't: it already means "ten" in Roman numerals.
Most educated Westerners, at the very least, are familiar with the basics of Roman numerals. We know that "I" means "one," "V" means "five," and "X" means "ten" at the very least. We are therefore accustomed to seeing "X" as a number as well as a letter; this presents the slightest possible learning curve, one that most of us already surmounted when we learned to read which Super Bowl is being played this year. And finally, while they are letters rather than numbers, they meld as well as can be expected with our digit characters:
This little article is being written in HTML, of course, which is, practically speaking, limited to ASCII. (Really, limited to 8-bit extensions of ASCII; Unicode can also be used, but its support, particularly with the commonly available Web fonts, is sporadic in the ranges higher than eight bits.) While we could adopt some other symbols out of the enormous Unicode code books, these would not necessarily display reliably in all browsers; therefore, we will employ this convention throughout this article and this web site.
Print Characters
For print characters, the options are naturally much broader. Literally any shape imaginable is possible; we need merely include these in existing fonts and find a way to include them in our digital documents prior to printing. (For some time, special characters were included on many typewriters, particularly in the Dozenal Society of Great Britain.) However, writing by hand is not yet entirely extinct; some displays are very limited; and the styles of our current fonts do put some boundaries on what type of characters we can consider. Some limiting considerations include:
- We already have 0--9; we've already decided that it's best to leave these characters as they are. Our new characters will have to mesh with these old ones; that is, they'll have to be of the same general style and size. One informal way of expressing this idea, commonly heard among dozenalists, is that oour new digits must look like numbers.
- They must be reasonably easy to write by hand. Many of
us still frequently write by hand, and we must accomodate
these. As a practical matter, this means:
- The new digits must be writable in one or two strokes; that is, we must be forced to lift the pen never, or only one time.
- The new digits must not be too elaborate to be easily writable.
- The new digits must be easily distinguishable; that is, though they must "look like numbers," they must not be easily confused with other numbers.
- They must be amenable to simplification for limited displays. The famous "seven-segment" display, for example, often still found on cheap pocket calculators and old gas pumps, requires construction of numerals in only seven segments. Our new digits must be capable of being displayed in such simple displays.
- They must be as easily bootstrapped into existing fonts as possible. Naturally, we don't want to have to rewrite all of our fonts; we will want to continue using the many beautiful fonts that are already available. Our characters should be as easily integrated into these fonts as we can make them. For example, a rotated numeral, the way that six and nine are rotated, might be a good idea; provided, however, that it is not too easily confused with another numeral.
The number of proposals for different characters along these lines, as well as along others, are far too innumerable to go over in any detail here; Michael deVlieger, current president of the DSA, presented an admirably succinct yet complete synopsis of the various proposals in the Duodecimal Bulletin (pdf). However, I suggest that one of these proposals excels in all four of these categories, as well as possesses a distinguished historical pedigree: the "Pitman" numerals, named for their inventor, famed shorthand developer and dozenalist Sir Isaac Pitman:
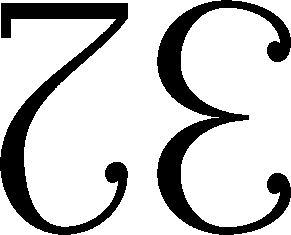
These characters mesh very well with the old ones, since they are simply rotations of currently existing characters. In other words, they look like numbers. They are easy to write by hand, and both can be written without lifting the pen from the paper; indeed, a few minutes of practice makes them second nature. They are no more confusable with other numerals than six is confusable with nine; and in those cases where confusion might arise, we can simply resort to the same method we have with six and nine; namely, place a line under the bottom side. They are easily adaptable to seven-segment displays, as shown below:
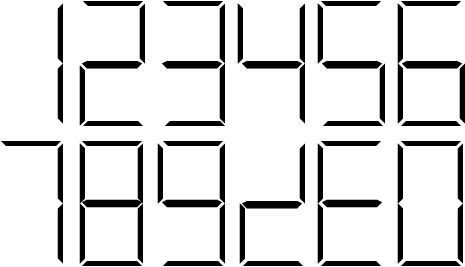
Some adaptation is necessary for the X (ten), to be sure; but hardly any more than for eight, two, five, zero, or nine, which look little like their written forms when confined to such limiting displays. And finally, they are easily bootstrapped into existing fonts. Ideally, of course, specially designed characters will be produced for current fonts; however, failing that, they are easily "faked" by simply rotating existing symbols. This will serve as an adequate stopgap while we wait for professional font designers to catch up to the numerical state-of-the-art.
Many other schemes possess some of these characteristics; this author does not think that any other scheme possesses all of them. Therefore, the Pitman numerals are recommended for use with the dozenal system.
All document produced for print on this site, such as the SDN Synopsis, the Primer on Dozenalism, and TGM are produced using these characters.